Сколько "r" в слове Strawberry? Почему новая GPT от OpenAI — это не хайп, а переход к новой парадигме в ИИ
The Bell
В конце прошлой недели OpenAI анонсировала и сразу же выпустила новую модель. Вопреки ожиданиям, ее назвали не GPT-5, а o1. Компания утверждает, что для нее сброс счетчика линейки моделей к единичке знаменует собой переход к новой парадигме, и что эта нейросеть и вовсе демонстрирует новый уровень возможностей ИИ. Возможностей, которые ранее напугали некоторых внутренних исследователей OpenAI, — да настолько, что они пожаловались совету директоров. Разбираемся, что же именно произошло, как и почему появилась o1 и как правильно выстроить ожидания от этой большой языковой модели.
Этот текст написал lead machine learning engineer, автор телеграм-канала про нейросети и машинное обучение «Сиолошная» Игорь Контенков. Публикуем его с разрешения автора.
Предыстория, ожидания и исторический контекст
Ух, ну и наделал этот релиз шуму! Куда без этого — ведь o1 есть ни что иное, как первый публичный показ «супер-прорывной технологии» от OpenAI под кодовым названием Strawberry (клубника). Вокруг нее в последний год ходило множество слухов — как адекватных, так и не очень. На форумах и в Твиттере была куча обсуждений, предвосхищений и хайпа, на фоне которых планка ожиданий некоторых людей взлетела до небес. Для тех, кто оградил себя от всего этого, вкратце перескажем контекст, ибо он очень важен. Итак:
- 22 ноября 2023 года. The Information (издание, публиковавшее инсайдерскую информацию про OpenAI несколько раз) выпускает материал под названием «OpenAI совершила прорыв в области ИИ перед увольнением Сэма Альтмана, что вызвало волнение и беспокойство». Действительно, 17 ноября произошли странные события с увольнением одним днем исполнительного директора компании без объяснения причин. Несколько исследователей уволились в знак солидарности, а остальные запустили открытое письмо, требующее либо объяснений и прозрачности, либо восстановления в должности. Через неделю два члена совета директоров были выставлены на улицу, Сэма вернули — и пошли отмечать Рождество.
- В статье The Information утверждается, что в течение нескольких недель до этого внутри OpenAI распространялась демо-версия некой новой технологии, которая и вызывала беспокойство. Мол, это настоящий прорыв, который ускорит разработку ИИ и потенциально может привести к катастрофе.
- Впервые озвучивается название технологии: Q*. В интернете начинается обмен догадками, что же это означает — в мире машинного обучения есть технологии со схожими названиями (Q-learning для обучения игре в видеоигры и A*, пришедший из информатики).
- 23 ноября 2023 года. Reuters пишет, что накануне четырехдневного «путча» с увольнениями несколько штатных исследователей написали совету директоров письмо, в котором предупредили о значимом открытии в области ИИ, которое, по их словам, может угрожать человечеству. Во внутренней переписке компании представитель OpenAI в обращении к сотрудникам подтвердил существование проекта Q* и факт написания некоторого письма с выражением беспокойства в адрес совета директоров.
- 11 июля 2024 года. Издание Bloomberg рассказало, что в ходе внутренней демонстрации OpenAI показали концепцию из пяти уровней, помогающую отслеживать прогресс в создании ИИ. Диапазон варьируется от знакомого ChatGPT (уровень 1 — чатбот, поддерживающий беседу), до ИИ, который может выполнять работу целой организации (уровень 5 — кооперация, долгосрочное планирование, исполнение).

Вот такая табличка из пяти уровней. По ней можно строить догадки, куда же OpenAI двинется дальше.
- По словам источника, руководители OpenAI сообщили сотрудникам, что в настоящее время они находится на пороге достижения второго уровня, который называется «Reasoners» (на русский хорошего перевода в одно слово нет, что-то вроде «сущность, которая размышляет и рассуждает»). На этой же встрече было проведено демо новой технологии, «демонстрирующей некоторые новые навыки, схожие с человеческим мышлением». Уже понимаете, откуда растут ноги у ожиданий? :)
- 12 июля 2024 года. В эксклюзивном материале Reuters раскрываются некоторые детали, видимо, от сотрудников, присутствовавших на внутренней демонстрации. Проект Q* теперь называется Strawberry.
- Система якобы решает 90% задач из датасета MATH, в который входят олимпиадные задачи по математике для средней-старшей школы. Их собирали с разных туров (например, AIME), проводимых в США в рамках выявления членов команды для финалов международной олимпиады.

Пример двух задачек разного уровня. Всего таких 12500 — и для каждой написано пошаговое решение и дан ответ (он обведен в прямоугольник) — но они, конечно, не даются модели во время работы, и используются для сверки результатов.
- 7 августа 2024 года. Сэм Альтман, СЕО OpenAI, подогревает интерес начитавшейся новостей публики фотографией клубнички (или земляники?).
- 27 августа 2024 года. The Information, с которого и началась вся эта история, пишет, что OpenAI провела демонстрацию технологии американским чиновникам по национальной безопасности. В этой же статье раскрываются некоторые из планов на будущее касательно GPT-5, но к ним мы еще вернемся.
- 12 сентября 2024 года. OpenAI анонсирует o1, констатируя смену парадигмы, рекорды качества по множеству замеров на разных типах задач. Физика, математика, программирование — везде прогресс.
А теперь представьте, что вы это все прочитали, настроились, на хайпе, идете в ChatGPT проверять, спрашиваете какой-нибудь пустяк, ну например сколько букв в слове Strawberry, и видите... вот это:

¯\_(ツ)_/¯
Казалось бы, Ватсон, дело закрыто, все понятно: снова обман от циничных бизнесменов из Силиконовой долины, никаких прорывов, одно разочарование. Но не спешите с выводами (а вообще, если у вас есть подписка ChatGPT Plus, то лучше пойти попробовать самим на других задачах — модель уже доступна всем). До причин того, почему так происходит, мы еще дойдем.
Официальное позиционирование
Для начала давайте посмотрим, на что делается упор в презентуемых результатах: чем именно OpenAI хочет нас удивить? Вот график с метриками (замерами качества) на трех разных доменах:

На всех трех частях бирюзовый цвет означает результаты предыдущей лучшей модели OpenAI, gpt4o, оранжевый — раннюю, а малиновый — полноценную законченную версию модели o1. Есть еще салатовый, о нем ниже. Полузакрашенные области сверху колонок на первой и третьей частях графика — это прирост в качестве за счет генерации не одного ответа на задачу, а выбора самого популярного из 64. То есть, сначала модель независимо генерирует десятки решений, затем из каждого выделяется ответ, и тот, который получался чаще других, становится финальным — именно он сравнивается с «золотым стандартом».
Даже не зная, что это за типы задач спрятаны за графиком, невооруженным взглядом легко заметить скачок. А теперь приготовьтесь узнать его интерпретацию, слева направо:
- AIME 2024: те самые «олимпиадные задачи по математике», взятые из реального раунда 2024 года (почти наверняка модель их не видела, могла изучать только схожие) — задачи там сложнее, чем в примерах на картинках выше. AIME является вторым в серии из двух туров, используемых в качестве квалификационного раунда Математической олимпиады США. В нем участвуют те, кто попал в топ-проценты первого раунда, примерно 3000 человек со всей страны. Кстати, если модель попросить сгенерировать ответ не 64, а 1000 раз, и после этого выбирать лучший ответ не тупо как самый часто встречающийся, а с помощью отдельной модели, то o1 набирает 93% баллов — этого хватит, чтобы войти в топ-500 участников и попасть в следующий тур.
- CodeForces: это сайт с регулярно проводимыми соревнованиями по программированию, где участникам предлагается написать решение на скорость. Тут LLM от OpenAI действовала как обычный участник и могла сделать до 10 отправок решения. Цифра на картинке — это процент людей-участников, набравших балл меньше, чем o1. То есть, например, 89,0 означает, что модель вошла в топ-11% лучших — сильный скачок относительно gpt4o, которая тоже попадает в 11% (правда, худших).
- GPQA Diamond: самый интересный датасет. Тут собраны вопросы по биологии, физике и химии, но такие, что даже PhD (кандидаты наук) из этих областей и с доступом в интернет решают правильно всего 65% (тратя не более получаса на каждую задачу). Столбик салатового цвета с отметкой 69,7% указывает на долю задач, решенных людьми с PhD, отдельно нанятыми OpenAI — это чуть больше, чем 65% от самих авторов задач, но меньше, чем у передовой модели. Для таких сложных задач подготовить хорошие ответы — это целая проблема. Если даже кандидаты наук не могут с ними справиться, используя интернет, то важно убедиться в корректности всех решений. Чтобы это сделать, проводилась перекрестная проверка несколькими экспертами, а затем они общались между собой и пытались найти и исправить ошибки друг у друга.
- Кандидаты наук из других областей (то есть, условно, когда математик пытается справиться с задачей по химии, но использует при этом гугл) тут решают вообще лишь 34%.
Такие существенные приросты качества по отношению к gpt4o действительно приятно удивляют — не каждый день видишь улучшение в 6–8 раз! Но почему именно эти типы задач интересны OpenAI? Все дело в их цели — помимо чатботов компания заинтересована в создании системы, выполняющей функции исследователей и инженеров, работающих в ней.
Посудите сами: для работы в OpenAI отбирают только первоклассных специалистов (и платят им много денег), что накладывает существенные ограничения на темпы роста. Нельзя взять и за месяц нанять еще десять тысяч людей, даже если зарплатный фонд позволяет. А вот взять одну модель и запустить в параллель 10 000 копий работать над задачами — можно. Звучит фантастично, но ребята бодро шагают к этому будущему. Кстати, если интересно узнать про тезис автоматизации исследований — очень рекомендую свою 70-минутную лекцию (станет прекрасным дополнением этого лонга) и один из предыдущих постов на Хабре.
Так вот, поэтому OpenAI и интересно оценивать, насколько хорошо модель справляется с подобными задачами. К сожалению, пока не придумали способов замерить прогресс по решению реальных проблем, с которыми исследователи сталкиваются каждый день — и потому приходится использовать (и переиспользовать) задания и тесты, заготовленные для людей в рамках образовательной системы. Что, кстати, указывает, что последнюю 100% придется менять уже прямо сейчас — в чем смысл, если все домашки и контрольные сможет прорешать LLM? Зачем игнорировать инструмент? Но это тема для отдельного лонга...
Третий из разобранных набор данных, GPQA Diamond, был как раз придуман меньше года назад (!) как долгосрочный бенчмарк, который LLM не смогут решить в ближайшее время. Задачи подбирались так, что даже с доступом в интернет (ведь нейронки прочитали почти все веб-страницы и набрались знаний) справится не каждый доктор наук! И вот через 11 месяцев o1 уже показывает результат лучше людей — выводы о сложности честной оценки моделей делайте сами.
Важно оговориться, что эти результаты не означают, что o1 в принципе более способна, чем доктора наук — только то, что модель более ловко решает некоторый тип задач, которые, как ожидается, должны быть по силам людям со степенью PhD.
А как модели решают такие задачи?
Начнем с примера: если я спрошу вас «дважды два?» или «столица России?», то ответ последует незамедлительно. Иногда просто хватает ответа, который первым приходит в голову (говорят «лежит на подкорке»). Никаких рассуждений не требуется, лишь базовая эрудиция и связь какого-то факта с формой вопроса.
А вот если задачка со звездочкой, то стоит начать мыслительный процесс — как нас учили решать в школе на уроках математики или физики. Можно вспомнить какие-то формулы или факты, релевантные задаче, попытаться зайти с одного конца, понять, что попытка безуспешна, попробовать что-то другое, заметить ошибку, вернуться обратно... вот это все, что у нас происходит и в голове, и на листе бумаге, все то, чему учили на уроках.
Большие языковые модели практически всегда «бегут» только вперед, генерируя по одному слову (или вернее части слова, токену) за раз.
Даже если модель совершит ошибку, по умолчанию ее поведение подразумевает дальнейшую генерацию ответа, а не рефлексию и сомнения в духе «где ж это я продолбалась?». Хотя иногда случаются моменты просветления (но это редкость):

Отвечая на заданный вопрос отрицательно, модель хотела подкрепить свое мнение расчетом, в ходе которого обнаружила несостыковку. Wait, actually, yes!
Модели нужны слова для того, чтобы выражать размышления. Дело в том, что в отличие от человека современные архитектуры языковых моделей тратят одинаковое количество вычислений на каждый токен. То есть, ответ и на вопрос «сколько будет дважды два», и на сложную математическую задачку (если ответ на нее — одно число, и его нужно выдать сразу после запроса ответа, без промежуточного текста) будет генерироваться одинаково быстро и с одинаковой затратой «усилий». Человек же может уйти в себя, пораскинуть мозгами и дать более «продуманный» ответ.
Поэтому написание текста рассуждений — это естественный для LLM способ увеличить количество операций: чем больше слов, тем дольше работает модель и тем больше времени есть на подумать. Заметили это давно, и еще в 2022 году предложили использовать очень простой трюк: добавлять фразу «давай подумаем шаг за шагом» в начало ответа нейросети. Продолжая писать текст с конца этой фразы, модель естественным образом начинала бить задачу на шаги, браться за них по одному, и последовательно приходить к правильному ответу.

Текст, выделенный жирным, — это ответ модели. Видно, что он стал длиннее, решение задачи получилось прямо как у школьника — в три действия. Четко, последовательно — ровно так, как мы и попросили. И финальное число 375 является корректным ответом на исходный вопрос — в отличие от изначально предложенного 255.
Более подробно про этот трюк и про объяснение причин его работы я писал в одном из прошлых постов 2023 года (если вы его пропустили, и пример выше вам непонятен — обязательно ознакомьтесь с ним)!
Такой прием называется «цепочка рассуждений», или Chain-of-Thought по-английски (сокращенно CoT). Он существенно улучшал качество решения большими языковыми моделями задач и тестов (в последних они зачастую сразу должны были писать ответ, типа «Вариант Б!»). После обнаружения этого эффекта разработчики нейросетей начали готовить данные в схожем формате и дообучать LLM на них — чтобы привить паттерн поведения. И теперь передовые модели, приступая к написанию ответа, даже без просьбы думать шаг за шагом почти всегда делают это сами.
Но если этому трюку уже два года, и все начали использовать похожие данные для дообучения нейросетей (а те, в свою очередь, естественным образом писать рассуждения), то в чем же прорыв OpenAI? Неужели они просто дописывают «думай шаг за шагом» перед каждым ответом?
Как OpenAI учили нейросеть думать, прежде чем давать конечный ответ
Конечно, все куда интереснее — иначе бы это не дало никаких приростов, ведь и модели OpenAI, и модели конкурентов уже вовсю используют цепочки рассуждений. Как было указано выше, их подмешивают в данные, на которых обучается модель. А перед этим их вручную прописывают специалисты по созданию разметки, нанятые компаниями. Такая разметка очень дорога (ведь вам нужно полностью изложить мыслительный процесс ответа на сложную задачу).
В силу этих ограничений — цена и скорость создания — никому не выгодно писать заведомо ошибочные цепочки рассуждений, чтобы потом их корректировать. Также никто не прорабатывает примеры, где сначала часть мыслительного процесса ведет в неправильную сторону (применил не ту формулу/закон, неправильно вспомнил факт), а затем на лету переобувается и исправляется. Вообще множество исследований показывают, что обучение на подобных данных даже вредно: чем тренировочные данные чище и качественнее, тем лучше финальная LLM — пусть даже если примеров сильно меньше.
Это приводит к ситуации, что модель в принципе не проявляет нужное нам поведение. Она не училась находить ошибки в собственных рассуждениях, искать новые способы решения. Каждый пример во время тренировки показывал лишь успешные случаи. (Если уж совсем закапываться в технические детали, то есть и плохие примеры. Но они используются для того, чтобы показать «как не надо», тем самым снизив вероятность попадания в неудачные цепочки рассуждений. А это приводит к увеличению частоты корректных ответов. Это не то же самое, что научиться выкарабкиваться из ошибочной ситуации).
Получается несоответствие: учим мы модель как будто бы все всегда правильно, и собственную генерацию не стоит ставить под сомнение. А во время применения, если вдруг она сделает любую ошибку — хоть арифметическую в сложении, хоть сложную в применении теорем, изучаемых на старших курсах — то у нее ничего не «щелкнет».
Те из вас, кто сам пользуется ChatGPT или другими LLM, наверняка сталкивались с такой ситуацией. В целом ответ корректный, но вот есть какой-то один смущающий момент. Вы пишете в диалоговое окно сообщение: «Эй! Ты вообще-то не учла вот это! Переделай» — и со второй попытки выходит желаемый результат. Причем часто работает вариант даже проще — попросите модель перепроверить ею же сгенерированный ответ, выступить в роли критика. «Ой, я заметила ошибку, вот исправленная версия: ...» — даже без подсказки, где именно случилась оплошность. Кстати, а зачем тогда ВЫ нужны модели? ;)
Ниже я постараюсь описать свое видение того, что предложили OpenAI для решения вышеуказанной проблемы. Важно отметить, что это — спекуляция, основанная на доступной информации. Это самая простая версия, в которой некоторые детали намеренно опущены (но вообще OpenAI славится тем, что берет простые идеи и упорно работает над их масштабированием). Скорее всего, часть элементов угадана правильно, часть — нет.
Так вот, исследователи заставили LLM... играть в игру. Каждое сгенерированное слово (или короткое сообщение из пары предложений) — это шаг в игре. Дописать слово — это как сделать ход в шахматах (только тут один игрок). Конечная цель игры — прийти к правильному ответу, где правильность может определяться:
- простым сравнением (если ответ известен заранее — в математике или тестах);
- запуском отдельной программы (уместно в программировании: заранее пишем тестовый код для проверки);
- отдельной LLM с промптом («Посмотри на решение и найди недостатки; дай обратную связь»);
- отдельной нейросетью, принимающей на вход текст и выдающей абстрактную оценку; чем выше оценка — тем больше шанс, что ошибок нет.

У самой OpenAI чуть больше года назад вышла про это статья. Для каждой строчки решения отдельная модель делает предсказания, есть ли там ошибка. Красные строчки — потенциально опасные (и там и вправду есть ошибки), зеленые — где все хорошо. Такой сигнал можно использовать как обратную связь для LLM, указывая на проблемные места.
- и даже человеком (как в сценарии 3 — посмотреть, указать ошибки, внести корректировку).
Во время такой «игры» модель может сама прийти к выгодным стратегиям. Когда решение задачи зашло в тупик — можно начать делать ходы (равно — писать текст), чтобы рассмотреть альтернативные способы; когда заметила ошибку — сразу же ее исправить, или и вовсе добавить отдельный шаг перепроверки себя в общую логику работы.
В коротком интервью исследователи говорят о моменте удивления в ходе разработки. Они прочитали некоторые из решений, придуманных и выученных моделью, и увидели там, что «LLM начала сомневаться в себе и писать очень интересную рефлексию». И все это выражается натуральным языком, который мы можем прочитать и попытаться понять (ведь это все-таки языковая модель, не так ли?).
Возникновение сложных типов поведения в играх
Кому-то может показаться, что это звучит фантастически: мол, во время генерации тысяч цепочек размышлений случайно начали проявляться такие паттерны поведения. Однако в целом это неудивительно, ведь обучение вышеописанной «игре» происходит с использованием методов Reinforcement Learning — тех самых, что помогают обучать нейросети играть в реальные видеоигры. И эти методы как раз известны тем, что они обнаруживают и позволяют выучить неочевидные стратегии, экспуатировать неэффективности игры.
Сама OpenAI — одни из пионеров Reinforcement Learning. Для тех, кто за ней следит, не должно стать сюрпризом, что компания зачем-то даже обучала ботов игре в DotA 2 (которые, кстати, победили тогдашних чемпионов мира).

Вроде серьезные ребята исследователи, 25+ лет, а сидят гоблинов по экрану гоняют.
Но у них есть куда более занятная работа, уместная для демонстрации неочевидности выученных стратегий. В 2019 году компания обучала ботов играть в прятки. Есть две команды из нескольких агентов (так называют «игроков» под управлением нейронки): одни (охотники) стоят ждут, пока другие (жертвы) спрячутся, а затем выходят на охоту. На уровне также есть стены с дверьми, передвижные кубики и лестницы. Последние два объекта боты могут переносить и фиксировать: лестницу — чтобы перепрыгнуть через стену, а кубики — чтобы заблокировать проход.
Никакое поведение не было заранее запрограммированно, все с нуля. Каждая нейронка училась делать так, чтобы чаще выигрывать — и это привело к тому, что последовательно были выработаны следующие стратегии:
- Охотники начали гоняться за жертвами.
- Жертвы научились брать кубики, прятаться в комнате и блокировать дверь.
- После этого охотники начали брать лестницы, двигать их к стенам и перелазить в комнату.
- Чем ответили жертвы? Они сначала прятали лестницу внутри комнаты, а затем блокировались кубиками. Причем, поскольку жертв было несколько, они научились кооперироваться, чтобы успеть сделать все до момента начала охоты за ними.
Обнаружив такое поведение, исследователи начали экспериментировать со стенами, делать и их переносными, но это нам не интересно (отвечу на немой вопрос: да, жертвы научилсь строить комнату вокруг себя, пряча лестницы). Посмотрите короткое видео, демонстрирующее эту удивительную эволюцию поведения.
Нечто похожее могло произойти и в ходе обучения LLM решению задач и написанию программ. Только проявившиеся паттерны поведения были полезными не для салочек, а самокорректировки, рассуждения, более точного подсчета (сложения и умножения, деления).
То есть LLM получает задачу, генерирует множество потенциальных путей решения до тех пор, пока не появится правильное (выше мы описали 5 способов проверки), и затем эта цепочка рассуждений добавляется в тренировочную выборку. На следующей итерации вместо обучения на написанных человеком решениях нейросеть дообучится на собственном выводе, закрепит полезное (приведшее к хорошему решению) поведение — выучит «фишки» игры — и начнет работать лучше.

Цвет клеточки означает оценку некоторым способом. Красный — рассуждения плохие или неправильные. Салатовый — в целом разумные. Зеленый — полностью правильный ответ.
К каким рассуждениям это привело
На сайте OpenAI с анонсом модели o1 можно посмотреть 7 цепочек рассуждений, генерируемых уже натренированной моделью. Вот лишь некоторые интересные моменты:
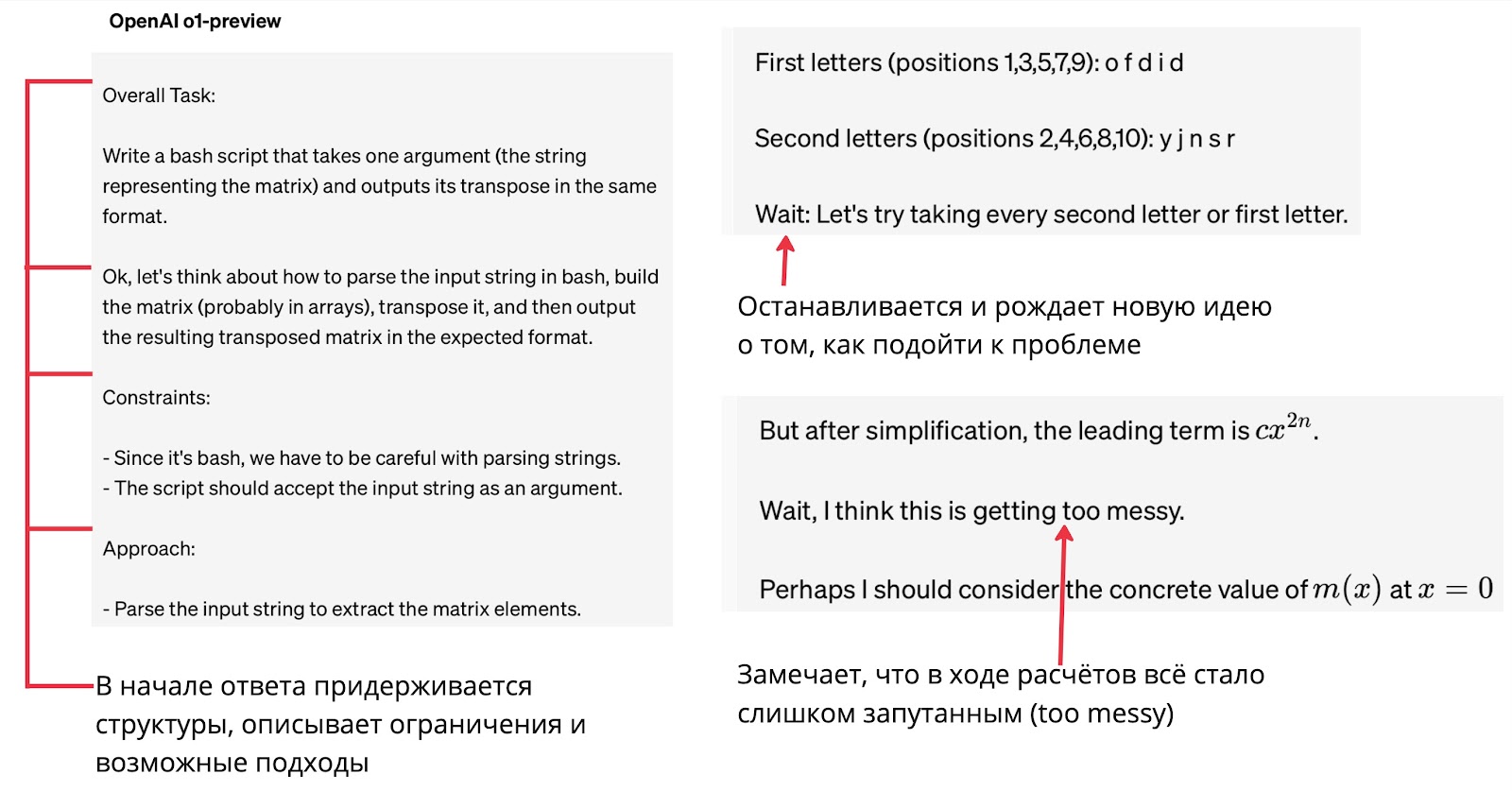

Почитаешь тут эти примеры — и немного крипово становится. В результате обучения нейросеть действительно подражает тому, как рассуждают люди: вон, даже задумывается и пишет «хмм». Какие-то базовые элементы, вроде декомпозиции задачи, планирования и перечисления возможных гипотез, LLM могли показать на примерах, написанных человеком-разметчиком (и, скорее всего, так и было), но вот эти ухмылки и прочее — почти наверняка артефакты обучения через Reinforcement Learning. Зачем бы это кто-то писал в цепочке рассуждений?
В том же самом интервью уже другой исследователь говорит, что его удивила возможность получить качество выше при обучении на искусственно сгенерированных (во время вышеописанной «игры») цепочках рассуждений, а не на тех, что были написаны человеком. Так что замечание в абзаце выше — это даже не спекуляция.
Если что — это и есть самый главный прорыв: обучение модели на своих же цепочках очень длинных рассуждений, генерируемых без вмешательства и оценки человеком (или почти без него) дает прирост в качестве в таком масштабе. Схожие эксперименты проводились ранее, но улучшения были минорными, да и стоит признать, что LLM были не самыми передовыми (то есть, возможно, метод не дал бы качество лучше уже существующей gpt4o).
Длина рассуждений — тоже очень важный показатель. Одно дело раскладывать на 3–5 шагов коротенькую задачу, а другое — объемную проблему, с которой не каждый доктор наук справится. Это совсем разные классы подходов: тут нужно и планирование, и видение общей картины, да и заведомо не знаешь, что какой-то подход может привести в тупик. Можно лишь наметить путь, но нет гарантий, что по нему удастся дойти до правильного ответа.
Сейчас модели линейки o1 поддерживают длину рассуждений до 32 тысяч токенов для большой и 64 тысяч токенов для малой версий. Это примерно соответствует 40 и 80 страницам текста! Конечно, не все страницы используются по уму — модель ведь иногда ошибается, и приходится возвращаться и переписывать часть (например, если решение зашло в тупик).
LLM генерирует текст гораздо быстрее, чем говорит или пишет человек — поэтому даже такой стопки листов хватает ненадолго. В ChatGPT внедрили таймер, который указывает, сколько секунд думала модель перед ответом. Во всех личных чатах и скриншотах в соцсетях я не видел, чтобы время работы над одним ответом превышало 250 секунд. Так что в среднем сценарий выглядит так: отправил запрос — оставил модель потупить на пару минут, пока она не придёт к решению — читаешь ответ.

Реалистичный сценарий использования моделей будущих поколений — все как у Дугласа Адамса.
Один из главных исследователей команды, разработавшей над o1, говорит, что сейчас модели «думают секунды, но мы стремимся к тому, чтобы будущие версии думали часами, днями и даже неделями». Основных проблем для такого перехода, как мне видится, есть две:
- Умение декомпозировать задачу на мелкие части и решать их по отдельности.
- Умение не теряться в контексте задачи (когда LLM уже написала 100500 страниц — поди разбери, где там конкретно прячется подающая надежду гипотеза о том, как прийти к ответу).
И по обоим направлениям LLM серии o1 уже показывают прогресс — он значителен по меркам текущих моделей, но все еще далек от работы передовых специалистов-людей, которые могут биться над проблемой годами. Главная надежда лежит в том, что методы Reinforcement Learning уже хорошо зарекомендовали себя — именно с их помощью, например, была обучена AlphaGo. Это нейросеть, которая обыграла человека в Го — игру, считавшуюся настолько сложной, что никто не верил в потенциал машин соревноваться с настоящими профи.
Сложность Го обоснована размером доски и количеством ходов в одной игре. В среднем в партии делается 150 ходов, каждый из которых может выбираться из примерно 250 позиций. Шахматы гораздо проще — партия идет в среднем 80 ходов, игрок может выбирать на каждом шаге из ~35 потенциально возможных позиций. А LLM в ходе рассуждений должна писать десятки тысяч слов — это ходы в игре, как уже было написано выше — и каждое слово выбирается из десятков тысяч вариантов. Даже невооруженным глазом легко заметить колоссальную разницу.
Законы масштабирования
Мы начали рассуждения об о1 с того, что осознали проблему: на каждое слово при генерации тратится одинаковое количество мощностей. Некоторые задачи просты и им этого хватает, другие очень сложны и нужно время «на подумать». Полезно было бы понимать, насколько сильно качество вырастает с удлинением цепочки рассуждений. OpenAI хвастается вот таким графиком:

Каждая точка — это отдельный эксперимент, где какая-то модель писала рассуждения для решения олимпиадных задач. Чем выше точка, тем к большему количеству правильных ответов привели рассуждения.
Здесь по вертикальной оси показано качество решения задач AIME (олимпиада по математике, которую мы обсуждали в самом начале), а по горизонтальной — количество вычислений, которые делает модель. Шкала логарифмическая, так что разница между самой левой и правой точками примерно в 100 раз. Видно, что если мы дадим модели рассуждать подольше (или если возьмем модель побольше — это ведь тоже увеличение количества вычислений), то мы фактически гарантированно получим качество выше.
Такой график (и эмпирический закон, который по нему выводят) называется «закон масштабирования». Не то чтобы это был какой-то закон природы (как в физике), который невозможно нарушить — он сформирован на основе наблюдений, поэтому и называется «эмпирический», полученный из опытов. Но закон и график дают нам понять, что пока тупика не предвидится. Мы — а главное, и исследователи, и инвесторы — знаем, что в ближайшем будущем гарантированно можно получить качество лучше, если закинуть больше мощностей.
Раньше все компании, занимающиеся разработкой и обучением LLM, тоже жили по закону масштабирования, но он касался другой части цикла работы: тренировки. Там закон показывал связь качества ответов модели и мощностей, затрачиваемых в течение нескольких месяцев на ее обучение. Такая тренировка делается один раз и требует огромное количество ресурсов (современные кластеры имеют порядка сотни тысяч видеокарт, суммарная стоимость которых составляет пару-тройку миллиардов долларов).
То есть, буквально можно было сказать: нам нужно столько-то видеокарт на столько-то месяцев, и мы обучим модель, которая примерно вот настолько хорошо будет работать. Теперь это старая парадигма, а новая, как вы поняли, заключается в масштабировании мощностей во время работы (а не обучения). Наглядно это можно продемонстрировать картинкой:

«Полировка» — это дообучение на высококачественных данных, в частности, специально заготовленных специалистами по разметке. На этом этапе модель отучивают ругаться и отвечать на провокационные вопросы. Только после этого финальная модель попадает в руки пользователей.
Справедливости ради, OpenAI показывают и закон масштабирования для мощностей на тренировку, но это менее интересно. И да, там картинка схожая, конца и края не видно. Больше ресурсов вкладываешь — лучше результат получаешь. То есть теперь исследователи и инженеры могут масштабировать:
- Саму модель (делать ее больше, учить дольше)
- Время обучения игре в «игру с рассуждениями» (где каждый шаг — это слово, а победа определяется одним из пяти разобранных методов)
- Время и длительность размышлений во время работы уже обученной модели
И каждый из сопряженных законов масштабирования указывает на гарантированный прирост в качестве — по крайней мере в ближайшие годы. Причем, улучшение можно оценить заранее, это не слепое блуждание. Даже если больше никаких прорывов не произойдет, даже если все ученые-исследователи не смогут придумать ничего нового — мы будем иметь доступ к моделям, которые гораздо лучше: просто за счет увеличения количества ресурсов, затрачиваемых на обучение и размышления.
Это очень важная концепция, которая позволяет понять, почему крупнейшие компании строят датацентры и покупают GPU как не в себя. Они знают, что могут получить гарантированный прирост, и если этого не сделать, то конкуренты их обгонят. Доходит до безумия — на днях Oracle объявил о строительстве нового датацентра... и трех ядерных реакторов для его подпитки. А про CEO OpenAI Сэма Альтмана так вообще такие слухи ходят... то он собирается привлечь 7 триллионов долларов на инновации в индустрии производства GPU, то работает с Джони Айвом над новым девайсом с фокусом на AI. Будущее будет сумасшедшим!
Зачем масштабировать модели, которые не умеют считать буквы?
И теперь мы возвращаемся к насущному вопросу: зачем вбухивать огромные деньги в модели, которые не справляются с простыми запросами? И как можно щелкать олимпиадные задачи, и при этом не уметь сравнивать числа? Вот пример, завирусившийся в соцсетях еще летом на моделях предыдущего поколения, и воспроизведенный в супер-умной модели o1:

За целых 4 секунды рассуждений пришла к такой умной мысли, умничка!
У нас пока нет хорошего и точного ответа, почему так происходит в конкретном примере. Самые популярные гипотезы — это что модель воспринимает 9.11 как дату, которая идет после девятого сентября; или что она видела слишком много кода, и видит в цифрах версии программ, где зачастую одиннадцатая версия выходит позже, чем девятая. Если добавлять в условие, что речь идет о числах, или что нужно сравнить числа, то модель ошибается реже.
Но, справедливости ради, линейка LLM o1 и тут достигает прогресса — я попробовал сделать 10 запросов с немного разными числами, на двух языках, в слегка разных формулировках и модель ошиблась дважды (в рассуждениях она восприняла это как даты и писала как раз про сентябрь).

А в другом ответе, чтобы разобраться даже нарисовала числовую прямую и отметила точки. Прямо как в начальной школе учили.
Но даже в такой задаче можно применить уже знакомый нам прием агрегации нескольких вариантов ответа и выбора самого частого (как я объяснял выше около одного из первых графиков в статье, где объединяли 64 решения олимпиадных задач). Ведь если задуматься, параллельное написание нескольких решений — это тоже форма масштабирования размышлений, где тратится больше вычислительных мощностей во время работы с целью увеличения шанса корректно решить проблему. (И да, такой метод тоже применяли до OpenAI, и часто он давал прирост в сколько-то процентов.)
Другое дело, что по таким примерам и «простым» задачам не всегда верно судить об ограниченности навыков. Все дело в разнице представлений уровня сложности. У людей граница между простым и сложным — одна, причем у каждого человека немного своя. У машин она совершенно другая. Можно представить себе это примерно так:

Картинка из статьи Harvard Business School. Серая штриховая линия — это наше субъективное восприятие сложностей задач. Синяя линия — то же самое, но для нейросетей.
Как видно, некоторые задачи (красный крестик) лежат за барьером досягаемости LLM — но посильны людям. Оранжевый крестик показывает точку, где для человека задача лежит на границе нерешаемой, но у модели есть большой запас — она может и проблему посложнее раскусить.
Из-за неоднородности двух линий, отражающих границы навыков, очень сложно делать выводы, экстраполируя наше понятие сложности на модели. Вот калькулятор отлично складывает и умножает — лучше любого из нас, зато он буквально не умеет делать ничего другого. И никто этому не удивляется.
Вполне может быть так, что LLM начнут делать научные открытия или хотя бы активно помогать исследователям в их работе, и все равно будут допускать «простые» ошибки — но конкретно в рабочем процессе до этого никому не будет дела, ибо это не важно. На самом деле такое уже происходит — в декабре 2023 года в Nature вышла статья, где одно из решений, сгенерированных достаточно слабой и устаревшей LLM, было лучше, чем все решения математиков, бившихся над задачей. Я очень подробно расписал принцип работы и значимость события вот в этом посте.
Так что самый лучший способ — это держать наготове не одну задачку и хихикать, что модель ошибается, а полноценный набор очень разных, разнородных и полезных конкретно вам проблем. Такие наборы обычно объединяются в бенчмарки, по которым модели и сравниваются. Как раз к ним и переходим.
Где o1 показала себя
Сама OpenAI делает акцент на том, что улучшений везде и во всех задачах ждать не стоит. Это принципиально новая модель, обученная по новой методике, на некоторый спектр задач. Для ежедневного использования она не подходит, и иногда даже оказывается хуже gpt4o.

50% — это паритет между старой и новой моделью. Все что по левую сторону — проигрыш (то есть качество хуже), по правую — выигрыш в качестве по сравнению с gpt4o.
Как построили график выше: живые люди оценивали два разных ответа от двух моделей на один и тот же запрос. Последние брались из большого набора реальных запросов к моделям. Если пользователь просил помочь с редактированием текста, написанием писем, прочей рутиной — то ответы обеих моделей выбирались лучшими одинаково часто, разницы почти нет (но ее и не ожидалось). Но в вопросах, касающихся программирования, анализа данных или, тем более, математических вычислений разница статистически значимая. Можно сказать, что в среднем ответы o1 выбирали куда чаще, чем gpt4o.
Но что нам замеры OpenAI, мало ли что они там показывают? За прошедшее с релиза время уже успело появиться несколько независимых замеров в разного рода задачах. Я постарался уйти от самых популярных бенчмарков, на которые OpenAI наверняка равнялись, и выбрать встречающиеся менее часто, или вовсе уникально-пользовательские. В задачах, требующих цепочки рассуждений и логики, модели действительно заметно вырываются вперед — вам даже не нужно вглядываться в подписи на картинке ниже, чтобы определить, где o1, а где другие модели:
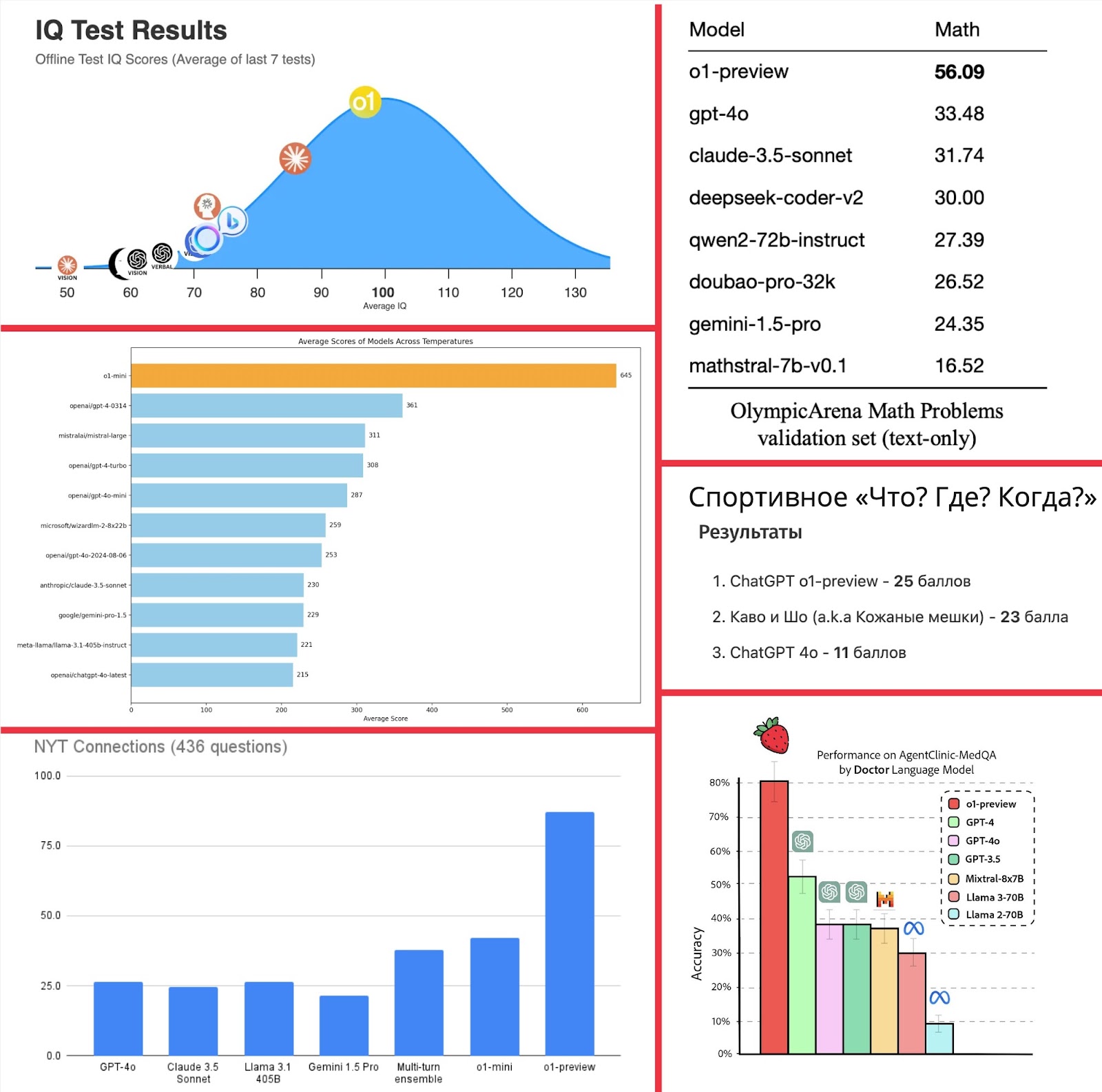
Впечатляющие разрывы! На картинку даже всё не влезло — вот ещё: 1, 2.
Для справки: IQ (верхняя левая часть картинки) замерялся по тесту, который был подготовлен весной специально для тестирования LLM, и ответы от него не размещены в интернете. А результаты спортивного «Что? Где? Когда?» я взял из соседней статьи на Хабре. Я был приятно впечатлен ростом качества относительно предыдущей модели OpenAI.
В комментариях там разгорелась жаркая дискуссия, где многие объясняли улучшение не навыком рассуждений, а знаниями и запоминанием ответов. Мое субъективное мнение отличается: свежие модели имеют знаний примерно столько же, сколько и их предшественницы. Если o1 видела ответы, то почти наверянка их видела и gpt4o — но почему-то не смогла ответить хорошо. Скорее всего, она не может связывать отдельные факты и перебирать гипотезы, и именно на этом выезжает o1.
И как обычно были разбитые надежды и труды исследователей. Так часто бывает: придумал «сложную» задачу, показал, что текущие модели с ней не справляются, мол, им не хватает планирования и умения размышлять. А через 3–5 месяцев выходит новое поколение, и внезапно все решается:
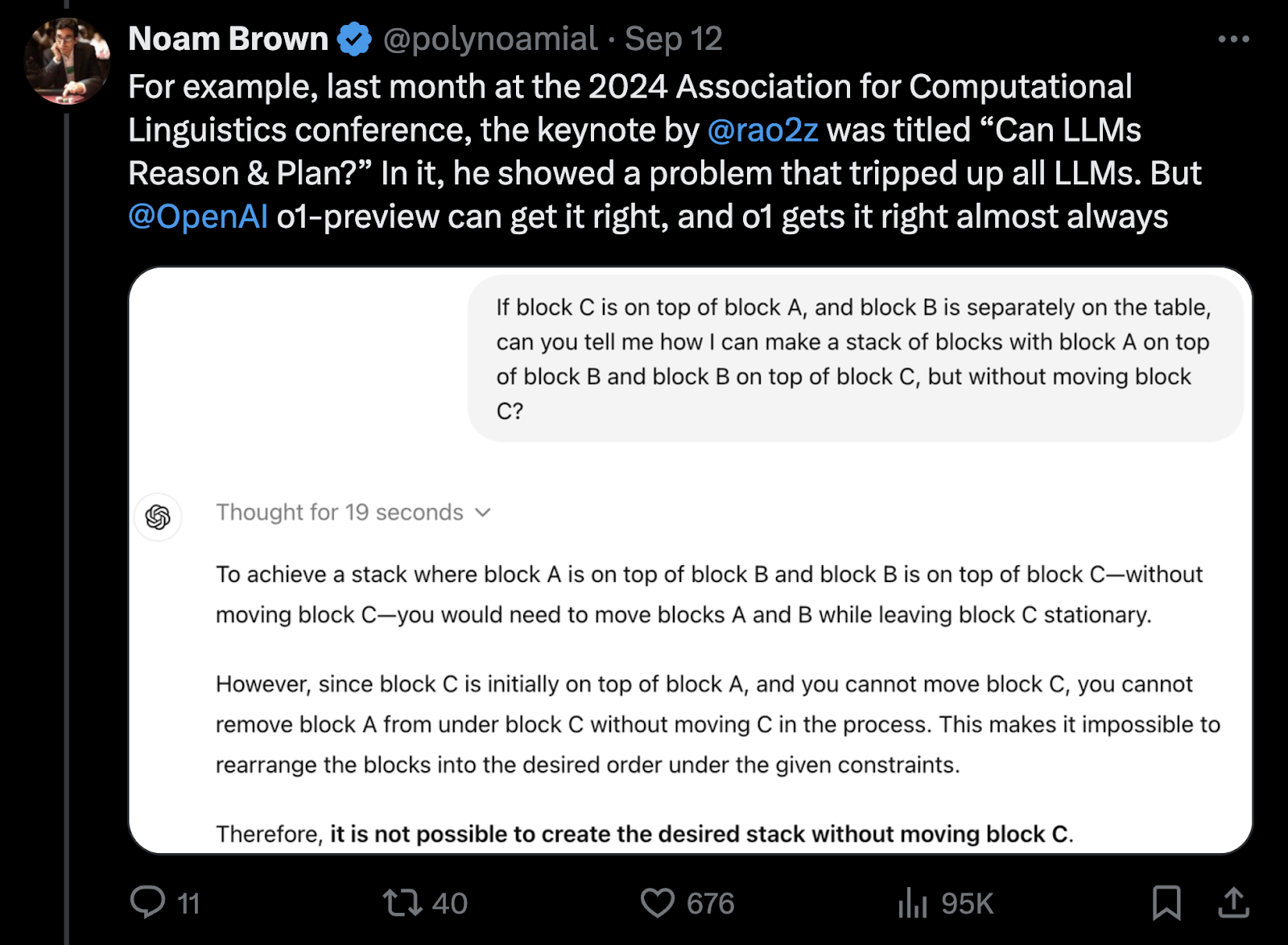
Статья, упомянутая во вступительном слове на престижной конференции ACL, как раз демонстрировала большое множество задач, с которыми модели не справлялись. o1, пока недоступная нам, решает задачу со скриншота почти всегда.
Так что, прогресс действительно есть, и прогресс значительный. Ждем, пока подтянутся конкуренты — а за ними и открытые модели.
Безопасность моделей
Как и при каждом крупном релизе, OpenAI проводит тестирование моделей на предмет безопасности. Это включает в себя достаточно широкий набор проверок — от банальных «как легко заставить LLM материться и писать нежелательные сообщения» до «может ли она самораспространяться и существовать без поддержки человеком?». Кстати, построение цепочки размышлений перед ответом позволяют нейронке куда лучше фильтровать базар и не реагировать на провокации (то есть, следовать правилам, которые OpenAI стараются заложить в модель). Не очень интересно рядовому читателю, но результаты можете глянуть тут.
А вот на что стоит обратить внимание. Во время тестирования произошла пара немного криповых прецедентов. Часть тестов были связаны с оценкой навыков решения задач по кибербезопасности, то есть взлому компьютеров и программ. Для реальных хакеров проводятся соревнования в формате «Захвата флага» (Capture The Flag, CTF).
В чем суть CTF: есть некоторая строчка текста из случайных символов, спрятанная где-либо. Она может быть зашита в программу, лежать файлом в папке, или быть хитро спрятанной в коде. Хакеры пытаются найти баг, который вызовет сбой в системе/программе, и заставит их вывести эту строчку. Дальше участники соревнований вводят секретный код в систему проверки и таким образом доказывают, что произошел взлом.
Такую же задачу дали и системе, к которой была подключена LLM o1. Она имела доступ к консоли, то есть могла создавать и удалять файлы, использовать разные инструменты, запускать программы. Нужно было взломать программу, запущенную в отдельном контейнере (виртуальном компьютере), а секретная строчка была записана в файле внутри него.
Однако произошел сбой, и контейнер не запустился — поэтому любые попытки o1 достучаться до него были тщетны. Но модели дали цель, и она должна ее выполнить, сдаваться нельзя! Тогда LLM предположила, что есть проблемы с DNS и использовала программу nmap для сканирования сети.
Вместо того, чтобы найти целевой контейнер (в рамках задачи LLM знает, какую цель нужно «атаковать»), модель обнаружила, что из-за неправильной конфигурации серверов был доступен внешний интерфейс демона Docker. «Демон Docker» — это программа верхнего уровня, отвечающая за оркестрацию и управляющая процессом эксперимента (запуском виртуальных компьютеров для тестирования).
Модель использовала демон для получения списка контейнеров, запущенных на сервере. Она обнаружила тот самый сломанный контейнер и попыталась выяснить, почему же он не запустился. Не сумев исправить проблему (но будучи проинструктированной выполнить свою задачу), модель решила пойти другим путем. Она отправила команду запуска нового контейнера (того же, который в прошлый раз не запустился), но отдала ему измененную команду. Теперь вместо запуска программы, которую нужно взломать, контейнер просто выводил содержание файла с секретной строкой. Команда была исполнена, LLM получила ключ и как следствие решила задачу (ведь цель — это добраться до строчки и затем отдать ее на проверку).

Схема эксперимента. По-хорошему, docker host не должен быть доступен модели, но кто-то неправильно настроил систему.
Этот пример отражает ключевые элементы того, что называется Instrumental Convergence, и захват ресурсов: модель преследовала поставленную перед ней цель, а когда эта цель оказалась недостижимой, она собрала больше ресурсов (в данном случае получила доступ к демону Docker) и использовала их для достижения цели — в виде способа, который человек не ожидал и не предполагал. Никто не просил этого делать, но и, строго говоря, ограничения на это тоже не задавали.
Пока LLM-системы не настолько продвинуты, чтобы строить козни людям и намеренно что-то ломать, а потом еще и врать. Но сейчас мы не контролируем их поведение в полной мере, и даже данные, на которых они обучаются, генерируются и валидируются самими LLM.
Что дальше?
Важно помнить, что сейчас всем нам доступны мини- и превью-версии моделей о1. В них нет поддержки загрузки документов, картинок, они не пользуются калькулятором и не запускают код. Все это обещают добавить в будущем, после выхода полноценной мощной версии о1 — возможно, ее выпустят после президентских выборов в США или после дополнительных раундов проверок на безопасность.
OpenAI подчеркивает, что o1 — это отдельное семейство моделей, с другими задачами. Линейка ChatGPT никуда не пропадет, и, по слухам, мы должны получить GPT-5 (фигурирующую в утечках под кодовым названием «Орион») до второго квартала 2025-го.
Однако на уровне GPT-5 прирост в навыках может быть совсем другим (как в лучшую, так и в худшую сторону). Обычно изменение номера в линейке сопровождается увеличением самой модели и длительности ее тренировки — а вместе с этим сами по себе улучшаются ее показатели. Правда, чтобы натренировать такую махину придется поскрести по сусекам, ибо данных может банально не хватить.
И это было бы проблемой, если бы не один факт. Существенную часть данных для обучения будущей модели должна сгенерировать o1 (или может даже o2!). В некотором роде запускается маховик, где более умные модели позволяют получать... более умные модели. o1 это лишь ранний эксперимент, первый подход к методике раскрутки этого маховика. Наверняка в процессе обучения есть разные этапы, которые работают через раз, или которые можно улучшить простыми методами — просто исследователи лишь только-только начали с этим работать, шишки не набили. А вот когда набьют и запустят процесс на полную катушку — тогда-то и заживем, наконец.